
Article introductif 2/2, comment fonctionne l’analyse, la recherche et la reconnaissance d’empreinte digitale ?
Petit rappel, cet article est le second de notre série introductive sur la lecture d’empreinte digitale et fait suite à notre premier article intitulé un lecteur d’empreintes digitales, comment ça marche ? Nous vous invitons à le lire avant celui-ci pour une compréhension optimale.
Le troisième article, cette fois-ci sous la forme d’un tutoriel plus technique, porte quand à lui sur l’utilisation du lecteur d’empreintes R307 avec le Raspberry Pi. Cette introduction faite, passons à l’article !
Maintenant que nous avons fait le tour des différentes technologies pour l’acquisition des empreintes, il nous reste à comprendre comment il est possible d’analyser et de reconnaître deux empreintes similaires.
À priori, on pourrait imaginer que la comparaison de deux empreintes est une tâche très simple. Après tout, ne suffit-il pas de superposer les deux images pour voir si elles correspondent ? Et bien en fait non, dans un monde parfait dans lequel chaque capture d’image serait parfaite et ou chaque empreinte resterait toujours la même, cela fonctionnerait effectivement, mais ce n’est hélas pas comme ça que les choses se passent !
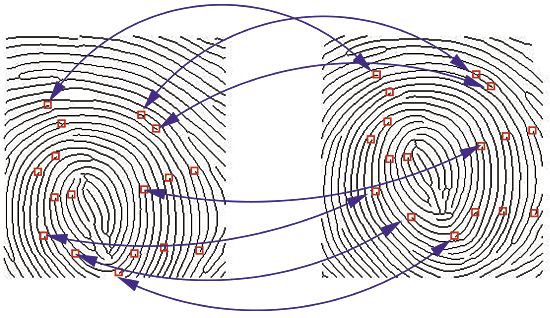
Source : Le Hong, Hai & Nguyễn, Hoá & Nguyen, Tri-Thanh. (2016). A Complete Fingerprint Matching Algorithm on GPU for a Large Scale Identification System.
Lors de la capture d’une empreinte, celle-ci n’est jamais parfaite, l’empreinte n’est jamais capturée dans son intégralité, la capture peut avoir quelques défauts, le capteur (ou même l’empreinte elle-même) peut être sale. L’empreinte peut aussi avoir un peu changé (une coupure, des travaux manuels qui ont abîmé quelques sillons, etc.). Sans compter que pour que l’image soit toujours la même, il faudrait que la pression appliquée par l’utilisateur lors de la lecture de l’empreinte soit, elle aussi, toujours exactement la même.
Vous l’aurez compris, la tâche est plus complexe que prévue, et comparer deux empreintes, ne revient en fait pas à comparer deux images telles quelles. En fait, la reconnaissance d’empreinte n’est absolument pas comme un mot de passe pour lequel on cherche une correspondance exacte. Dans le cas de la reconnaissance d’empreinte, tout est une question de taux de ressemblance, de probabilité, de motifs et de points de repères.
Le premier niveau de reconnaissance, le motif des empreintes.
Dans la reconnaissance d’empreinte, comme dans beaucoup de domaines liés à l’informatique d’ailleurs, on parle en fait de plusieurs niveaux de reconnaissance, chaque niveau supplémentaire permettant une correspondance plus précise, mais généralement aussi plus complexe.
Au début de cet article nous avons expliqué qu’une empreinte était en fait un ensemble de sillons arrangés généralement selon l’un de ces trois motifs, arche, spirale ou boucle, vous vous souvenez ? Et bien ce type de motif, c’est déjà un premier niveau de reconnaissance d’une empreinte digitale !

Alors évidement, à première vue ce niveau 1 ne parait pas bien précis. Avec un simple calcul on en déduit que chaque empreinte à au minimum 1 chance sur 20 (5%, le pourcentage de motif « arche ») de correspondre à n’importe quelle autre empreinte. Et c’est absolument vrai, mais n’allez pas pensez pour autant que ce niveau 1 de la reconnaissance est inutile, loin de là !
Bien sûr, si vous avez déjà deux empreintes connues et que vous souhaitez simplement les comparer, cela n’a pas beaucoup d’intérêt, le taux d’erreur serait beaucoup trop important. Mais maintenant, imaginez la situation suivante, vous avez d’un côté une empreinte appartenant à une personne inconnue, par exemple une empreinte retrouvée sur une scène de crime, et de l’autre une base de données de plusieurs centaines de milliers d’empreintes, par exemple un registre de police. Votre objectif, retrouver dans cette base de données la personne à laquelle appartient cette empreinte.
Et bien, d’un seul coup, ce niveau 1 devient très intéressant ! En effet, déterminer le type d’empreinte est un travail simple, très rapide, et dont le résultat peut sans problème être calculé dès l’enregistrement de l’empreinte puis stocké directement à côté de l’empreinte de base sans devoir être recalculée à chaque fois. Il s’agit donc d’un critère sur lequel le travail de tri prendra moins d’une seconde pour le dernier des ordinateurs du dernier des commissariats du dernier village du bout du monde. À une époque, il s’agit même d’un travail de tri qui aurait été possible manuellement par une petite équipe de moustachus armés d’une machine à café en ordre de marche !
Hors, ce premier tri vous permet déjà d’éliminer de 40% à 95% des suspects, vous libérant le temps nécessaire à la réalisation des vérifications plus poussées du niveau suivant !
Par ailleurs, ce niveau 1 ne se résume pas seulement au motif, mais également à son orientation, au doigt ciblé, etc ! Oui, 5% des empreintes ont un motif d’arche, mais combien d’empreintes ont un motif arche, penché de 12° dans le sens horaire, sur le pouce gauche ? Et si vous possédez plusieurs empreintes à chercher en même temps, la liste se réduit encore !
Je ne crois pas que les lecteurs d’empreinte numérique aient jamais utilisé le niveau 1 de la reconnaissance comme un critère de reconnaissance suffisant, et si cela a jamais été le cas, ça ne l’est plus depuis longtemps. Mais le niveau 1 reste employé, non pas comme un moyen de reconnaissance formel, mais bien comme un système de tri ultra rapide !
Le deuxième niveau de reconnaissance, les minuties.
Quand on parle de reconnaissance d’empreinte, on parle en fait généralement de ce niveau 2, lequel se base sur l’analyse de ce que l’on appelle des « minuties ».
Nous l’avons dit, une empreinte c’est un ensemble de sillons arrangés selon un schéma. En théorie, une empreinte digitale, ça devrait donc ressembler à l’image ci-dessous à gauche, un ensemble de lignes bien parallèles suivant un schéma parfait. Dans les faits, une empreinte digitale, ça ressemble plutôt à l’image de droite.

Certains sillons se rejoignent, d’autres se créent au milieu de nul part, certains s’arrêtent, il y a des coupures, des sillons qui bifurquent, etc. Au final on compte au moins 11 types de « défauts » différents et notables, parmi lesquels les plus remarquables sont les bifurcations (et leurs variantes), les fins et débuts de crêtes, les îlots, et les coupures de crêtes.
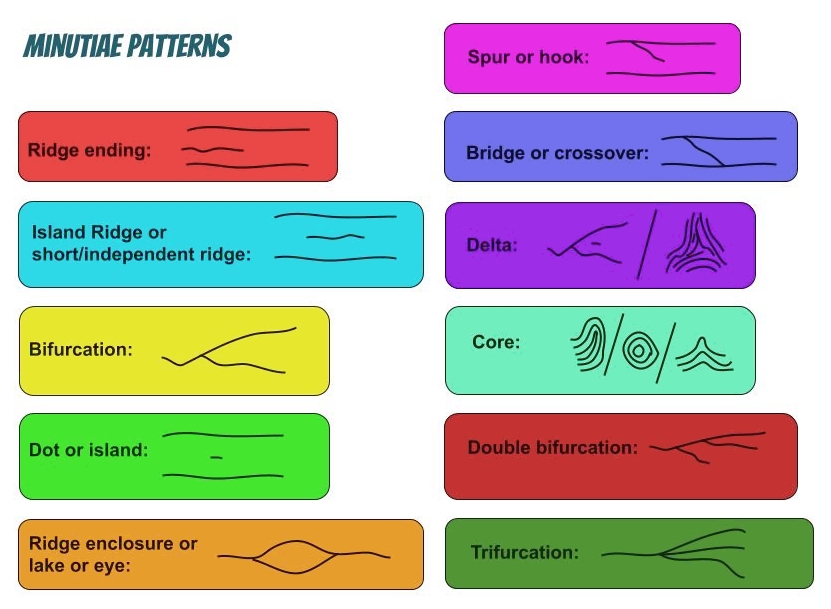
Tous ces défauts sont appelés des « minuties », et ce sont ces minuties qui vont nous servir à identifier une empreinte. Pour cela, on va noter l’emplacement de toutes les minuties visibles dans notre empreinte, leur type, leur orientation, et on va dresser une sorte de carte de leur positionnement relatif les unes par rapport aux autres.
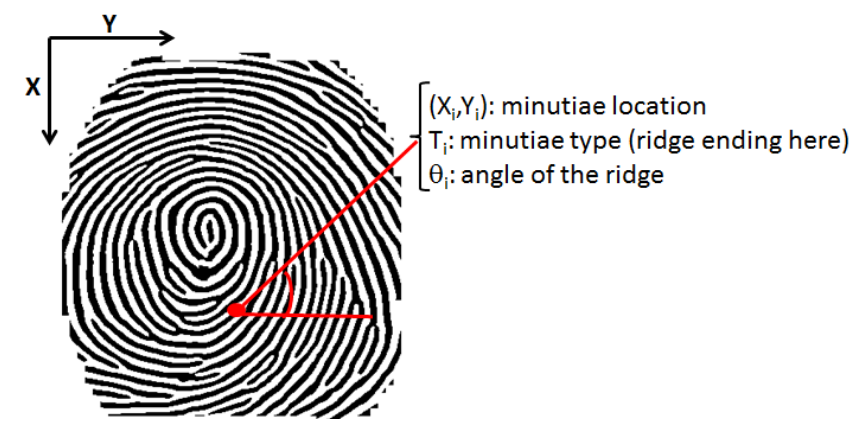
Par exemple, on pourrait dire que la minutie A, est une interruption de crête, à un angle de 12°, et que la minutie B est un îlot de 5 pixels, à un angle de 17°, et que la minutie B est située à 25 pixels sur une ligne à 32° au dessus de la minutie A. Il s’agit ici d’une méthode de représentation relativement simple, mais des méthodes beaucoup plus poussées sont utilisées et font intervenir des notions de mathématiques et de géométrie que je ne maîtrise absolument pas, si le sujet vous intéresse, voici un exemple de papier scientifique sur le sujet.

Source : Minutiae-based Fingerprint Extraction and Recognition, Naser Zaeri, 2010.
Au moment de comparer une empreinte, ce sont donc ces minuties qui vont êtres extraites et analysées. Comme nous l’avons dit plus tôt, l’image d’une empreinte n’est jamais une copie parfaite de celle-ci, et de nombreux défauts peuvent perturber l’image. C’est pour cette raison que les minuties sont stockées comme des références les unes par rapport aux autres, avec un niveau élevé de redondance. De façon à pouvoir être reconnues, non pas dans un cadre toujours identique, mais bien les unes par rapport aux autres, peu importe le cadre.
Par ailleurs, l’algorithme de correspondance ne va pas chercher une correspondance de toutes les minuties, ni une correspondance totale, car l’image d’une empreinte digitale étant toujours incomplète et de qualité variable, certaines minuties seront toujours manquantes. L’algorithme va donc plutôt chercher une correspondance suffisamment bonne et sur un nombre suffisamment élevé de minuties pour calculer un score de fiabilité quand à la correspondance des deux empreintes.
Un troisième niveau, plus rarement utilisé.
En plus du deuxième niveau, un troisième niveau de reconnaissance est possible. Celui-ci se base majoritairement sur la détection des pores de la peau, ainsi que les formes individuelles des crêtes, leur taille, leur orientation.
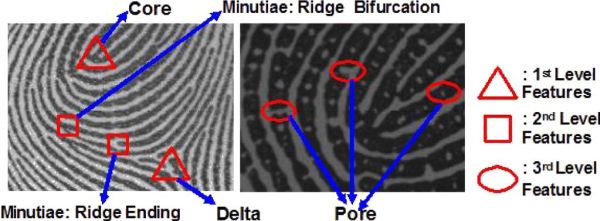
Source : Zhang et al., 2011
Ce niveau de détection reste aujourd’hui relativement rare, notamment car il demande des capteurs de très haute qualité, des empreintes très propres, etc., parce-que que le niveau 2 reste suffisant pour la vaste majorité des usages, et parce qu’ajouter davantage de minuties augmente de façon finalement peu utile l’espace nécessaire au stockage des données.
Un dernier défi, le stockage et la recherche des empreintes.
Si nous savons maintenant comment une empreinte est analysée afin de pouvoir être comparée, il reste un défi de taille, le stockage de ces empreintes. Là encore, on pourrait se dire que la solution est simple, il nous suffit de stocker les photos originales des empreintes.
Effectivement, la chose est faisable, après tout, stocker les empreintes de 10 millions de personnes, à raison de 10 empreintes par personnes, et pour des fichiers de 256*256 pixels, cela représente, environ 3 Ko par empreinte, sans aucune compression, c’est-à-dire 30 Ko par personne, soit 300 Go, un petit disque dur. Il serait donc tout à fait possible sur le plan technique de stocker toutes ces images, et c’est d’ailleurs à priori ce que fait la justice.
Seulement, tout l’intérêt d’une base d’empreintes ce n’est pas simplement de stocker les empreintes, mais bien de pouvoir rechercher des empreintes à l’intérieur de cette base ! Si nous stockons uniquement nos empreintes sous forme de photos, nous sommes obligés de refaire le processus de calcul pour chaque image de la base à chaque recherche d’empreinte. Autant vous le dire tout de suite, ce serait très long et très cher.
Par ailleurs, si on peut espérer (on a le droit de rêver) qu’un état est capable, dans un cadre centralisé, de stocker de façon sécurisée ce type de données hautement sensibles sur le plan de la vie privée, qu’en est-il pour des entreprises privées, toujours prêtes à vendre nos données personnelles, et pour des objets hautement décentralisés et par nature dérobables physiquement, comme les téléphones ?

Pour ces différentes raisons, la plupart du temps les empreintes ne sont en fait pas (ou pas uniquement) stockées sous forme d’images, mais sous forme de signature, généralement désignée comme un « template ». Cette signature contient habituellement un certain nombre de minuties (souvent uniquement les X plus importantes, ceci pour réduire le poids de la signature), lesquelles sont représentées selon leurs différentes propriétés selon un encodage adapté. Il peut exister différents formats de template, avec certains formats propriétaires, mais globalement et malgré quelques critiques, la norme ISO/IEC 19794-2 semble être ce que nous avons de plus proche d’un standard reconnu en la matière.
Grâce à cette représentation simplifiée, l’ensemble du traitement relatif à l’extraction des données est effectué une seule fois puis stocké, ne laissant plus à faire que le travail de comparaison et de calcul du taux de correspondance. Ainsi, en combinant des techniques de recherche rapide de niveau 1 et en stockant une partie du travail de niveau 2, il devient possible de faire des recherches dans de grands volumes de données dans des temps qui restent raisonnables.
Par ailleurs, cette forme de stockage permet de limiter les risques en cas de vol des données, car même s’il est théoriquement possible de recréer une empreinte qui produira une signature valide à partir d’une signature donnée, il semble pour l’heure impossible de reconstruire une empreinte parfaitement similaire à l’originale à partir de cette signature par essence incomplète.
De nombreux lecteurs d’empreintes sont capables d’effectuer directement ces traitements pour ne transmettre à l’ordinateur connecté que le template final, voir de sauvegarder en interne les templates et d’effectuer la recherche de correspondances directement en interne.
Mais au final, les empreintes digitales sont-elles vraiment fiables ?
Comme nous l’avons vu, contrairement à une vérification par mot de passe pour laquelle on obtient une réponse booléenne, avec une comparaison qui sera soit vraie, soit fausse, une empreinte retournera plutôt une probabilité, un taux de confiance quand à la correspondance de deux empreintes.
En matière d’empreinte et de traitement numérique, il n’existe jamais de certitude absolue, il nous appartient de fixer un seuil que nous considérerons comme adapté selon nos besoins. Ce seuil sera nécessairement un compromis entre le niveau de certitude, le temps de traitement et le taux de faux négatifs, c’est à dire d’empreintes qui auraient du correspondre, mais sont considérées comme différentes par le lecteur, par exemple en raisons de défauts dans l’image capturée.
Ce seuil peut et dois donc varier selon les besoins, il est la plupart du temps adaptable soit par l’utilisateur soit par le constructeur de l’appareil.

Pour déverrouiller votre téléphone ou votre porte de maison, certes, la sécurité est importante. Mais, si cela vous permet d’ouvrir sous la pluie avec le doigt un peu humide, il est préférable que votre empreinte soit considérée comme valide avec seulement 7 points correspondants et risques de faux positif de 0.00001%, plutôt que de passer la nuit dehors avec un taux d’erreur 10 fois plus faible.
Pour qu’une empreinte soit valide dans une affaire criminelle en revanche, on peut estimer qu’une fiabilité très forte est la règle primordiale, quitte à utiliser une fiabilité plus faible lors des phases de recherches pour limiter la puissance de calcul nécessaire, et donc le temps de recherche, et faire un second examen par la suite.
En France, le système judiciaire considère qu’il faut 12 minuties suffisamment proches de l’originale pour déclarer que deux empreintes correspondent. Ce chiffre représente globalement assez bien la moyenne en Europe. Aux USA en revanche, la barre est fixée à 8. Enfin, les français se souviendront du cas dit du « faux Xavier Dupont de Ligonnès », quand un homme avait été arrêté à tort à Glasgow, les enquêteurs ayant détecté une concordance partielle de ses empreintes avec celles de l’homme en fuite. Les enquêteurs n’avaient en fait que 5 points de correspondance…
Par ailleurs, il est à noté que des attaques sur les lecteurs d’empreintes ont non seulement été théorisées, mais également démontrées et exploitées. Les capteurs les plus performants peuvent être dotés de contre-mesures de sécurité plus ou moins efficaces, mais oui, dans une certaine mesure, le truc de la colle qu’on voit dans les films fonctionne vraiment. Pour plus d’infos sur le sujet, je vous conseille l’excellente vidéo de Scilabus sur le sujet.
Enfin, l’empreinte digitale souffre, en comparaison à un mot de passe de bonne qualité, de certains défauts, parmi lesquels on peut citer : l’impossibilité de changer son empreinte digitale (par exemple en cas de vol du fichier contenant l’empreinte originale) ; l’impossibilité de transmettre son empreinte digitale à une autre personne en cas de besoin ; la possible altération de l’empreinte digitale (par exemple en cas de blessure grave) ; l’existence physique de l’empreinte digitale qui permet sont utilisation illégitime par la contrainte ou la ruse.
J’espère que cet article vous aura intéressé et permis de mieux comprendre le processus complexe derrière la reconnaissance d’empreinte. Je vous retrouve dans quelques semaines pour le dernier article de notre série, avec cette fois un article plus technique pour apprendre à utiliser un lecteur d’empreinte digitale avec le Raspberry Pi. D’ici là soyez sage, et ne jouez pas avec la colle !










